Results and Conclusion
Contents
Summary
Music Recommender Systems (MRS), such as Spotify, aim at finding appropriate songs to recommend to users. Doing so successfully may increase user engagement by facilitating the creation of playlists by users, and by extending listening beyond the end of the existing playlists. Our goal in this exercise was to create a machine learning algorithm that would best suggest songs to an existing playlist, to the extent allowed by the timeline of this project and resources provided.
We chose a Random Forest model for predicting the genre of a given playlist, with accuracy on the test set of 70.5%. We also tried multiple other models, such as a simple logistic regression, a polynomial logistic regression, Linear Discriminant Analysis (LDA), Quadratic Discriminant Analysis (QDA) and Boosting, but none of these performed better than the selected Random Forest model. Once the genre of a given playlist was predicted, we recommended songs that belonged to that genre, and that would most closely resemble the features of the songs of the given playlist. Our final model used cosine similarity between the vector of features of the songs in the given playlist, and the vector of features of subset of songs of the same genre in the pool of songs to be recommended.
The input used was the Million Playlist Dataset, which we complemented with our secondary source of data taken from Spotify’s Web API. The final output of the model is the recommendation of a set of N songs (from a pool of 130,000 unique songs that we created) to be added to a given playlist. Given the unsupervised nature of this problem (the songs or playlists did not have a pre-defined class), we explored different ways to generate classifications to support our machine learning algorithm. Based on our Exploratory Data Analysis (EDA) and literature review, we decided to classify each song into five different genres (rock, poprock, pop, rap and others), and we used that to classify each playlist, according to the most frequent genre of songs in the playlist. Given the importance of having a similar distribution of playlists among the five classes for fitting the machine learning models, we manually created a sample dataset. More details about this process can be found in the “creating final dataset” section of this website. The picture below depics the whole process of our project.
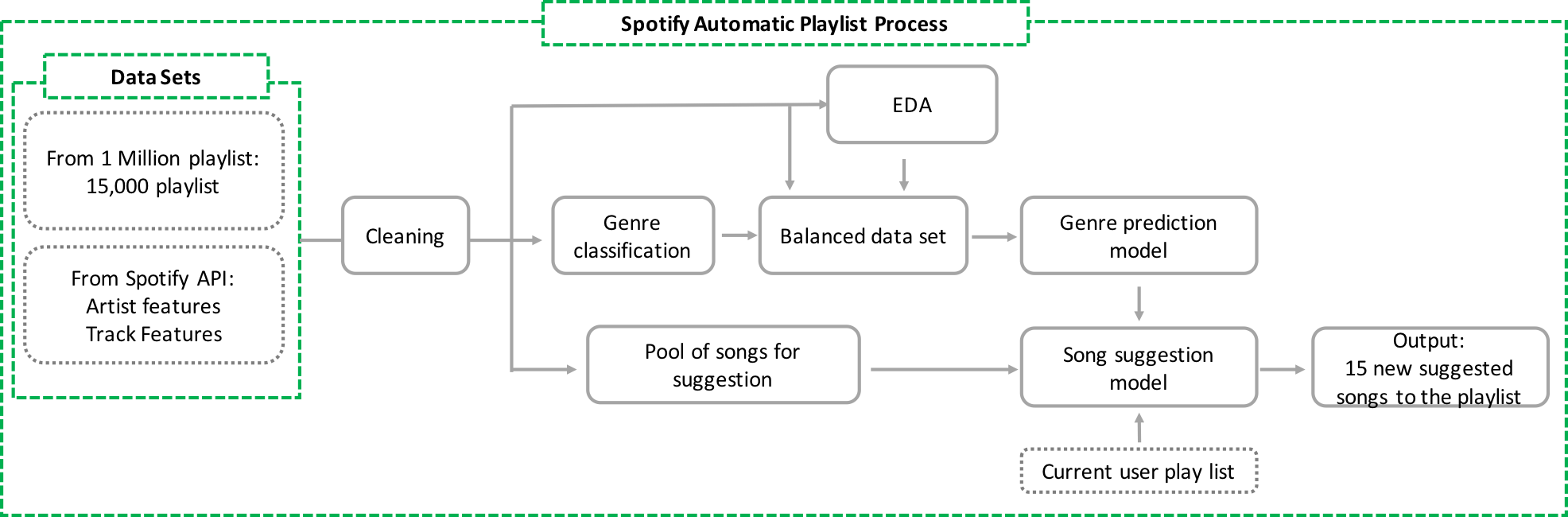
Results
We used different modeling methods for the 5-genres classification problem, using the variables from EDA part.
Variables:
‘duration_ms’, ‘time_signature’, ‘key’, ‘tempo’, ‘energy’, ‘mode’, ‘loudness’, ‘speechiness’, ‘danceability’, ‘acousticness’, ‘instrumentalness’, ‘valence’, ‘liveness’, ‘artist_followers’
Model Base decision tree model and random forest:
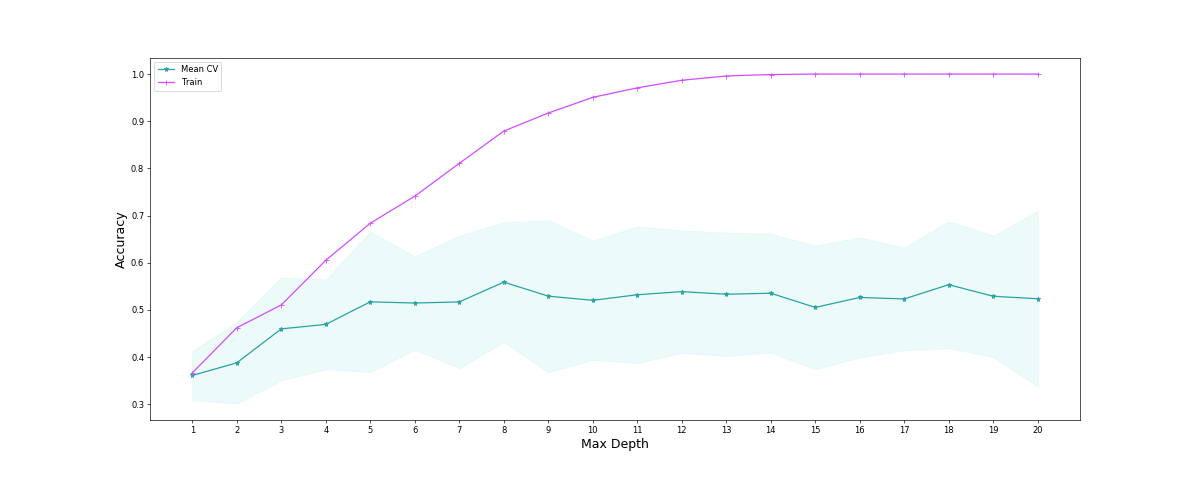
The random forest outperforms all of the other modeling methods based on the average of cross validation scores, thus we chose to use random forest as our prediction modeling method, even it has sign of overfitting. the base model for that is the decision tree with the depth of 16. In order to find the best depth for the baseline tree model, we used tunning of the depth as a hyperparameter of the signle decsiosn tree, in below picture you can see the results of the test and training score of the single decision tree for different depth level. The performance of the random forest on training set is1, while on the test set is 0.71 and the average of the cross validation scores on the test set is 0.67.
Below you can find the boxplot of the cross validation scores of the different models on the test set.
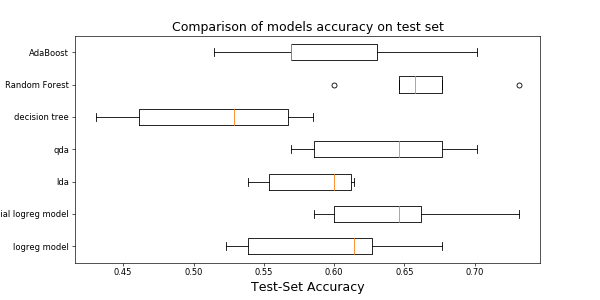
In below table you can find the performance summary of different modeling methods.
| Method | Train Score | Test Score | Average CV Test Score | Running Time | HyperParamether |
|---|---|---|---|---|---|
| Logistic regression with CV | 0.61 | 0.60 | 0.60 | 0.67 | |
| Polynomial logistic regression with CV | 0.75 | 0.69 | 0.65 | 2.74 | poly degree = 2 |
| LDA | 0.62 | 0.63 | 0.59 | 0.016 | |
| QDA | 0.66 | 0.62 | 0.63 | 0.01 | |
| Baseline model: Simple Decision Tree | 1 | 0.52 | 0.51 | 0.012 | depth = 16 |
| Random Forest | 1 | 0.71 | 0.67 | 1.03 | base tree depth = 16 number of trees = 500 |
| AdaBoost | 0.97 | 0.63 | 0.60 | 0.49 | Max depth = 6, number of estimators=60, learning rate=0.05 |
Explaination of the other methods:
Logistic regression with cross validation
The score of logistic regression with cross validation on the training and test sets are, 0.61 and 0.60 respectively. From this results, we can say there is room of adding more predicting variables to the model, in order to improve its predicting power.
Polynomial logistic regression with CV The performance of the model improved slighlty by adding polynomial feature to the x set. The average cross validation score on the training set is 0.75 and on the test is 0.65. And, this difference between the training and test score is the sign of overfitting in this model.
LDA The performance of the LDA is less than the other method, but it seems there is no sign of overfitting in this model due to close scores on the training and test set, which are, 0.62 and 0.59 respectively.
QDA The train score for the baseline decision tree is 0.66, while the test score is 0.63. The comparison and improvement of the QDA test score vs LDA score shows that the assumption the uniform coavriances is limitation for the performace of the model. And the flexiblity of QDA model, improved the reuslt slightly without the sign of overfitting.
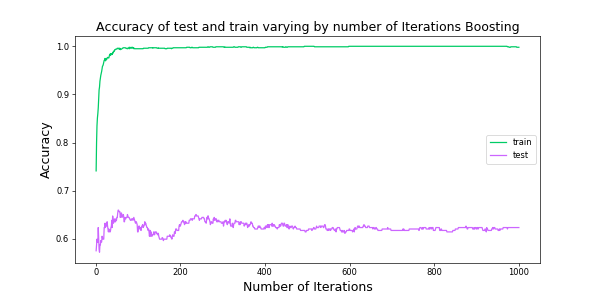
AdaBoost The training score of 0.97 vs the test score of 0.60 is the sign of overfitting in this model. And in below picture you can find the performance of the model on test set for different iterations. And as we saw with higher number of iteration is started to get overfitted more.
Song Recommendations Results
Here we compare the results of of our recommended songs for both the simple model recommender and the advanced model recommender. Remember that the simple model just randomly recommends songs from a pool based on predicted playlist genre while the advanced model recommends songs from a pool based on cosine similarity between the average features of a playlist and the song features in the pool.
It is imporant to mention that it is hard to objectively say that our model performs well or that it underperforms as recommending what are the best songs to be added to a given playlist is highly subjective and depends on each individual’s preferences. Given this, we proxy performance based on what we (subjectively) perceive by seeing the recommended songs and comparing these to the songs present in the playlist. We also proxied this by doing a simple online search about the songs in a given playlist and the recommended songs (focusing on what the online results suggest are the genre of the songs we searched.)
We present two output examples, one that displays our models in a good light and one in which we can see areas for improvement:
Example of good output:
Here’s an example where our model performs well:
The predicted genre of this example’s playlist based on our model is Pop Rock. The genre based on our classification of the playlist is also Pop Rock. So in this case, our model correctly classified this playlist. Here’s the actual playlist:
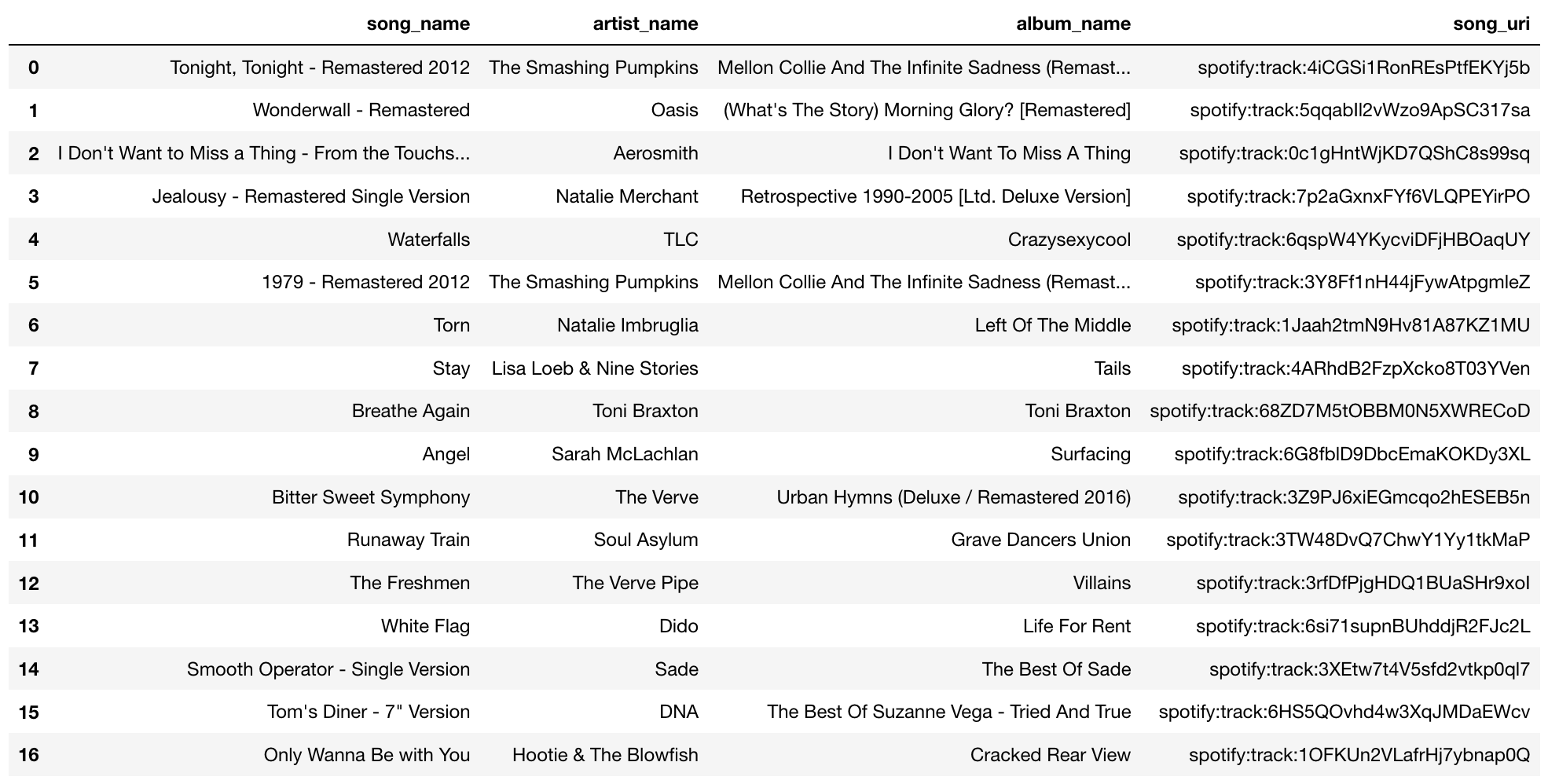
Notice that the playlist contains songs from artists such as “The Smashing Pumpking”, “The Verve”, “Aerosmith”, “Oasis”, “TLC”, “Toni Braxton”, “Dido”, and others. Under our subjective criteria, and some online searhing, we could classify these artists as being part of rock (ex. “Aerosmith”, “Smashing Pumpkins”, “Oasis”, “The Verve”, “Natalie Merchant”, “Soul Asylum”) or being part of pop (ex. “Dido”, “Natalie Imbruglia”, “Sarah Mclachlan”) and some contemporary R&B (ex. “Toni Braxton”, “TLC”, “Sade”). So, from a subjective point of view, we could mostly agree that this playlist is indeed a playlist that contains pop and rock songs. We could consider this an example of successful prediction. +1 for our classification model! Yay!
Now, here’s the simple recommender model’s set of songs suggested to be added to the playlist:
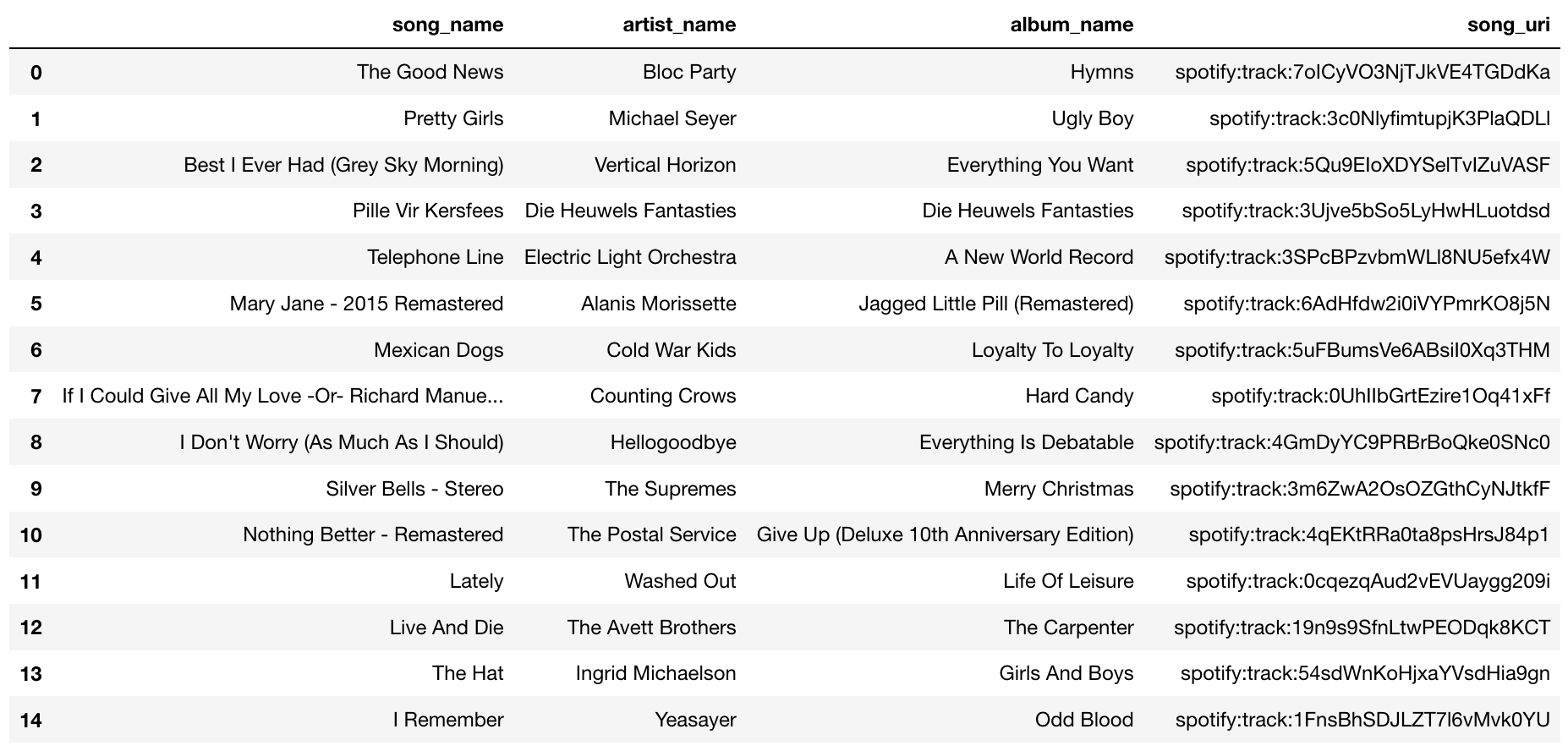
As you can see, some songs are of type rock (ex. “Bloc Party”, ), alternative rock (“Alanis Morissette”, “Michael Seyer”, “Vertical Horizon”, “Cold War Kids”, “Counting Crows”), some pop (“Washed Out”, “Hellogoodbye”) and oddly a christmas song by “The Suprmes” although they are known as being an R&B/Pop group. Although these are mostly rock and pop songs, these songs don’t “feel” like they belong in this playlist.
So, let’s see how the advanced model which uses cosine similarity does. Here’s the set of recommended songs:
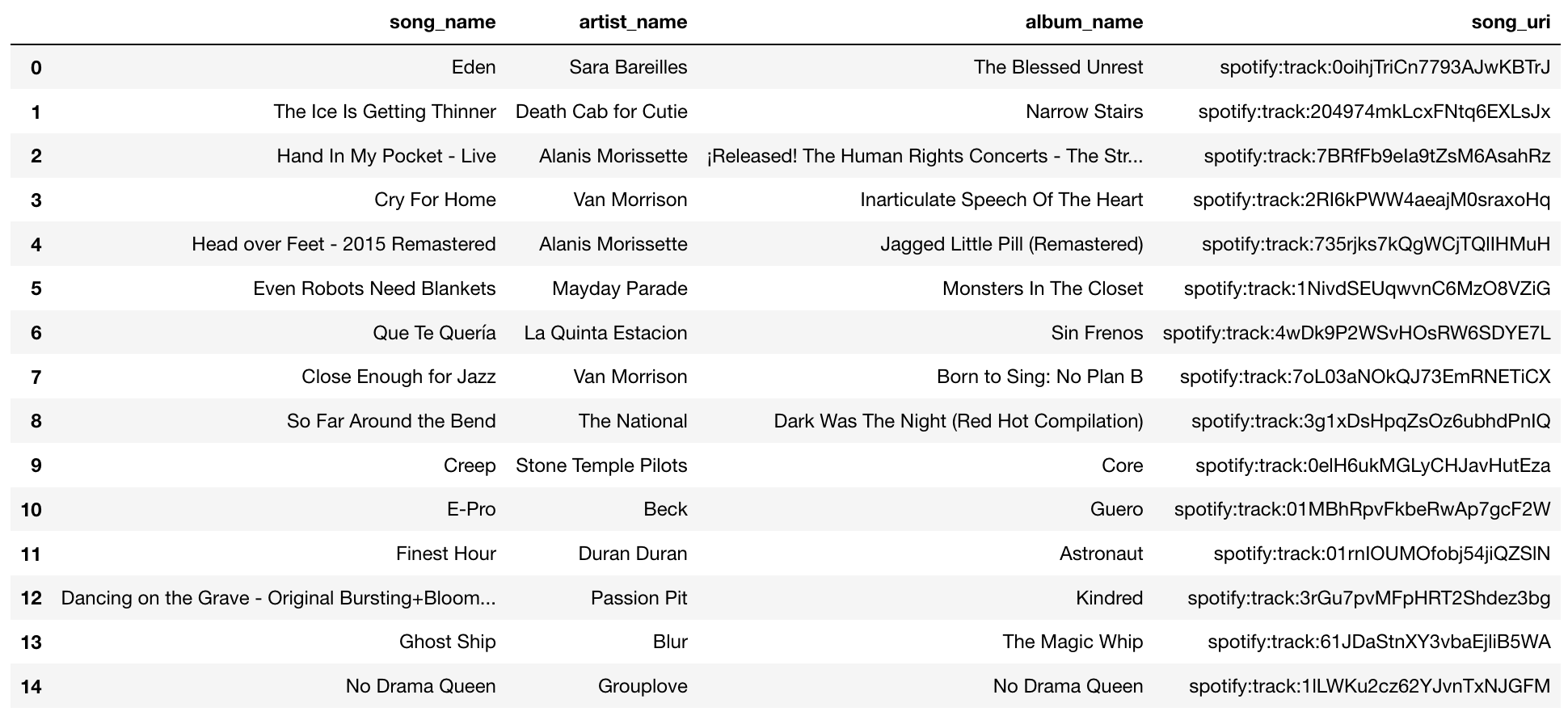
ok, a few things to notice. First, there are artists in this set seem to belong to rock and pop (ex. “Alanis Morissette”, “Van Morrison”, “Stone Temple Pilots”, “Beck”, “Duran Duran”, “Sara Bareilles”) which belong to rock, pop or R&B. So far it seems like a good set to be added. The order in this set matters, remember they are ranked based on cosine similarity, this implies that the song that most closely resembles the playlist is the first song “Eden” by Sara Bareilles. I decided to listen to this song, do I think it matches the songs in the playlist? Yeah, it sounds to me like a pop/R&B song, so it doesn’t feel as if it doesn’t belong there (unlike the christmas song recommended by the simple model). So we could consider this a case of successful recommendation. Yay!
Example of (not so) good output:
Here’s an example of where our model underperforms in a key criteria which we will explain below:
The predicted genre of this example’s playlist based on our model is Pop, but the genre based on our classification of the playlist in this case is Pop Rock. So here our model failed to correctly classify this playlist. Bad computer! (<- as Pavlos says). So let’s see what might be happening here. This is the actual playlist:
This is a sample of the actual playlist from the 1 Million Spotify Playlist dataset:
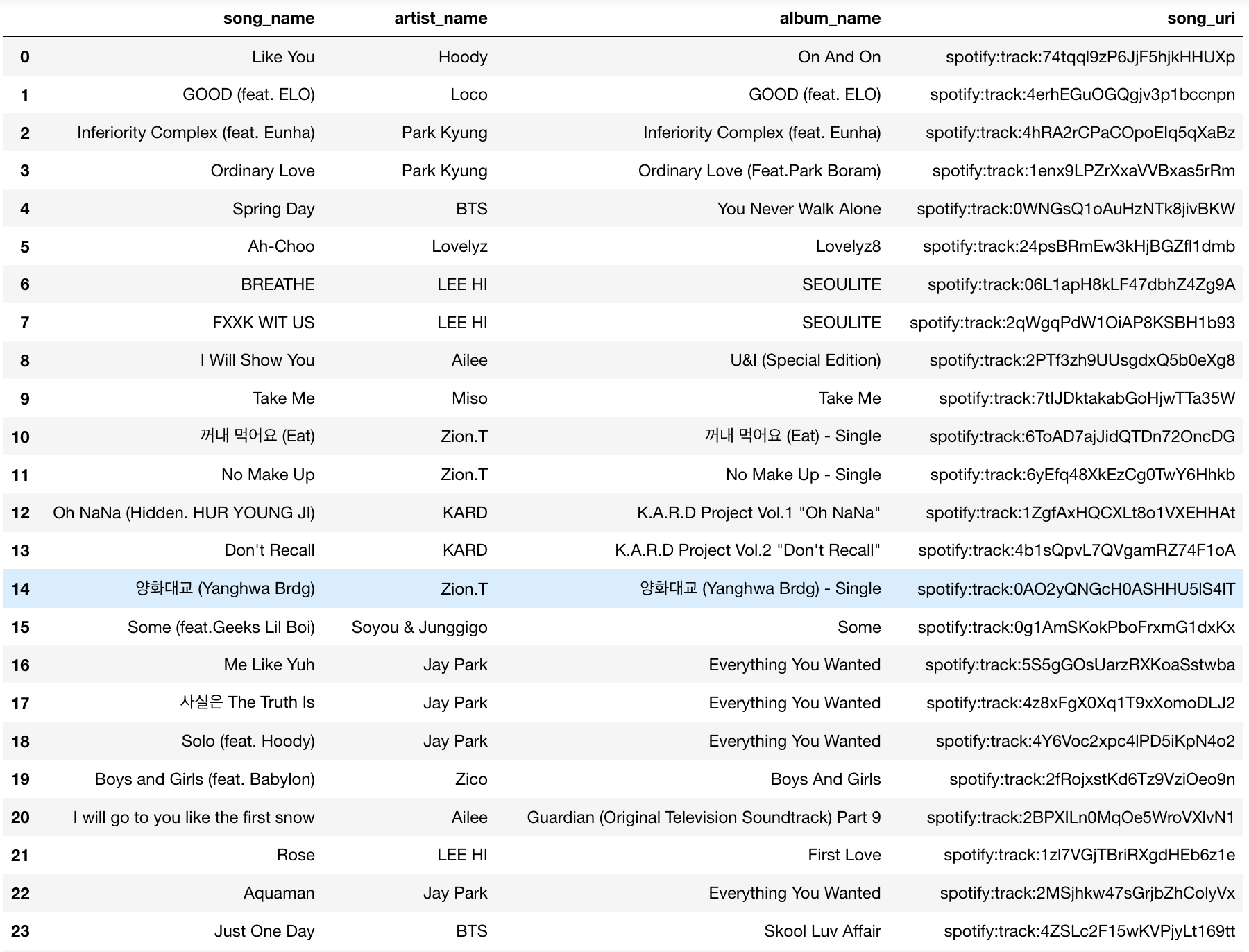
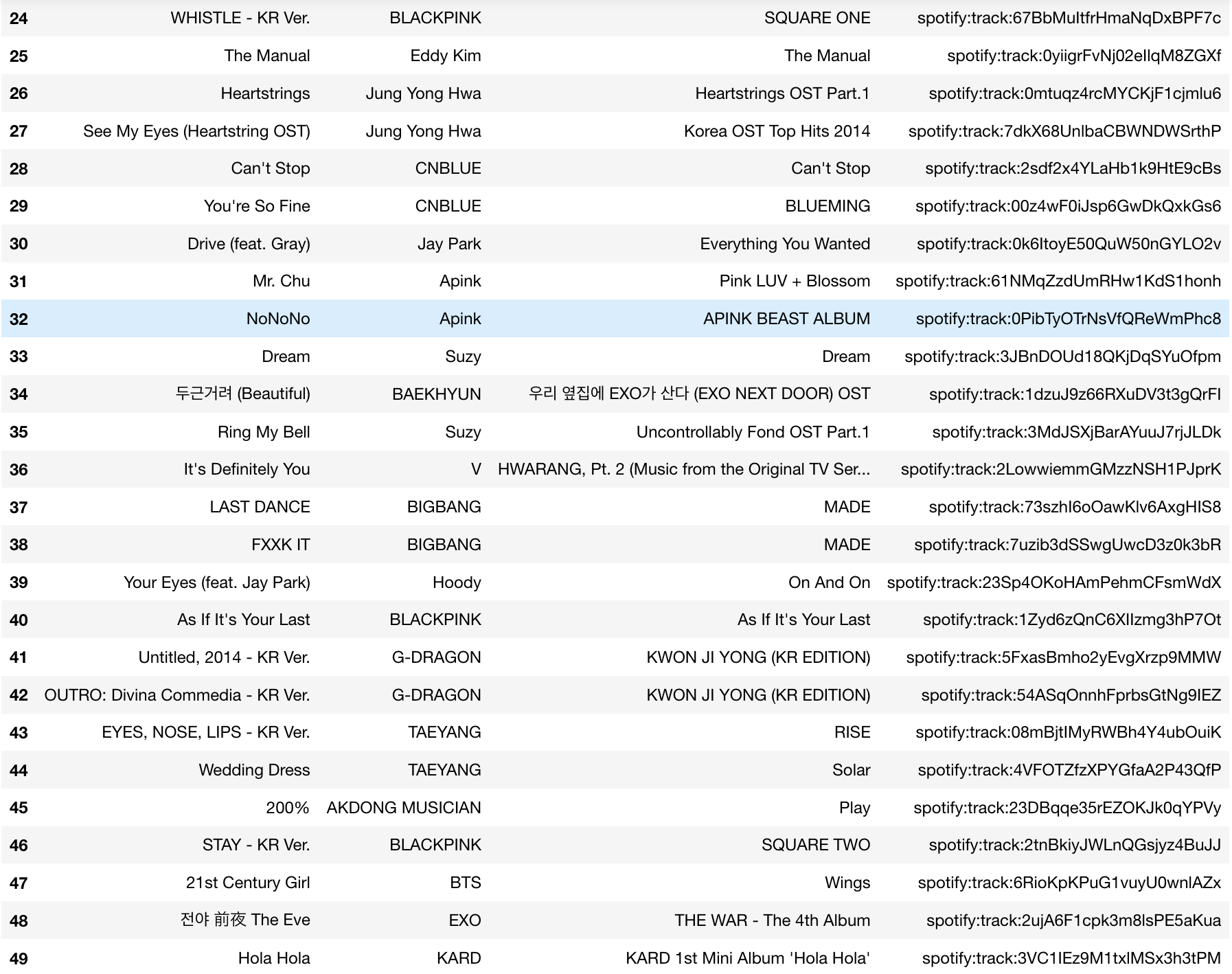
As you can see, most songs seem to be from Korea, from quick online searches, most songs seem to be of the genre hip hop, R&B and pop. Now, since our model mis-classified this playlist as pop, our recommendation models will not return songs from the playlists genre. Let’s take a look.
Here’s the simple model’s set of recommended songs to be added to the playlist:
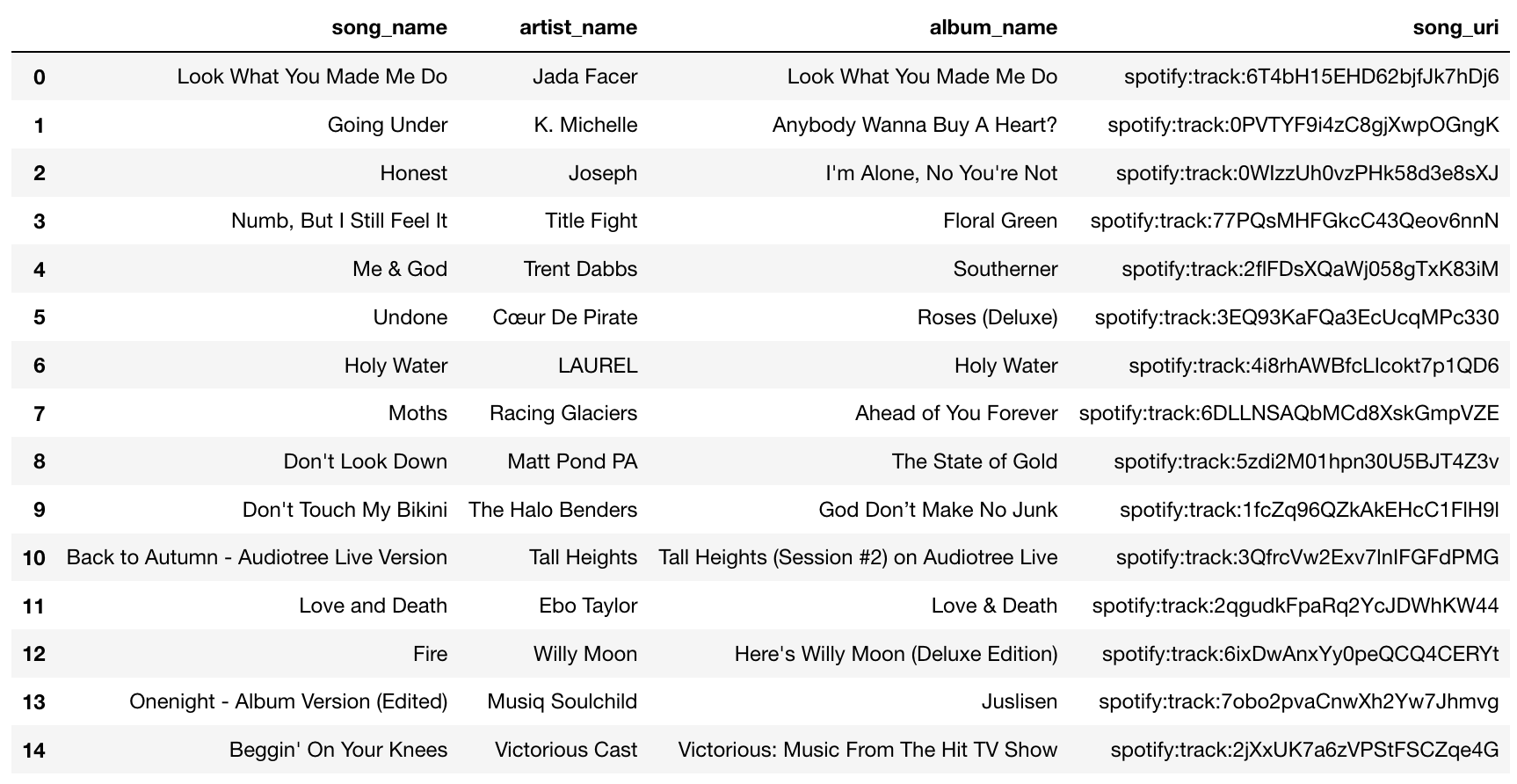
Ok, suggestions look terrible, non of them are korean songs as in the playlist. Alright, maybe the cosine similarity recommender does a better job, let’s see:
Here’s the advanced model’s (cosine similarity) set of recommended songs to be added:
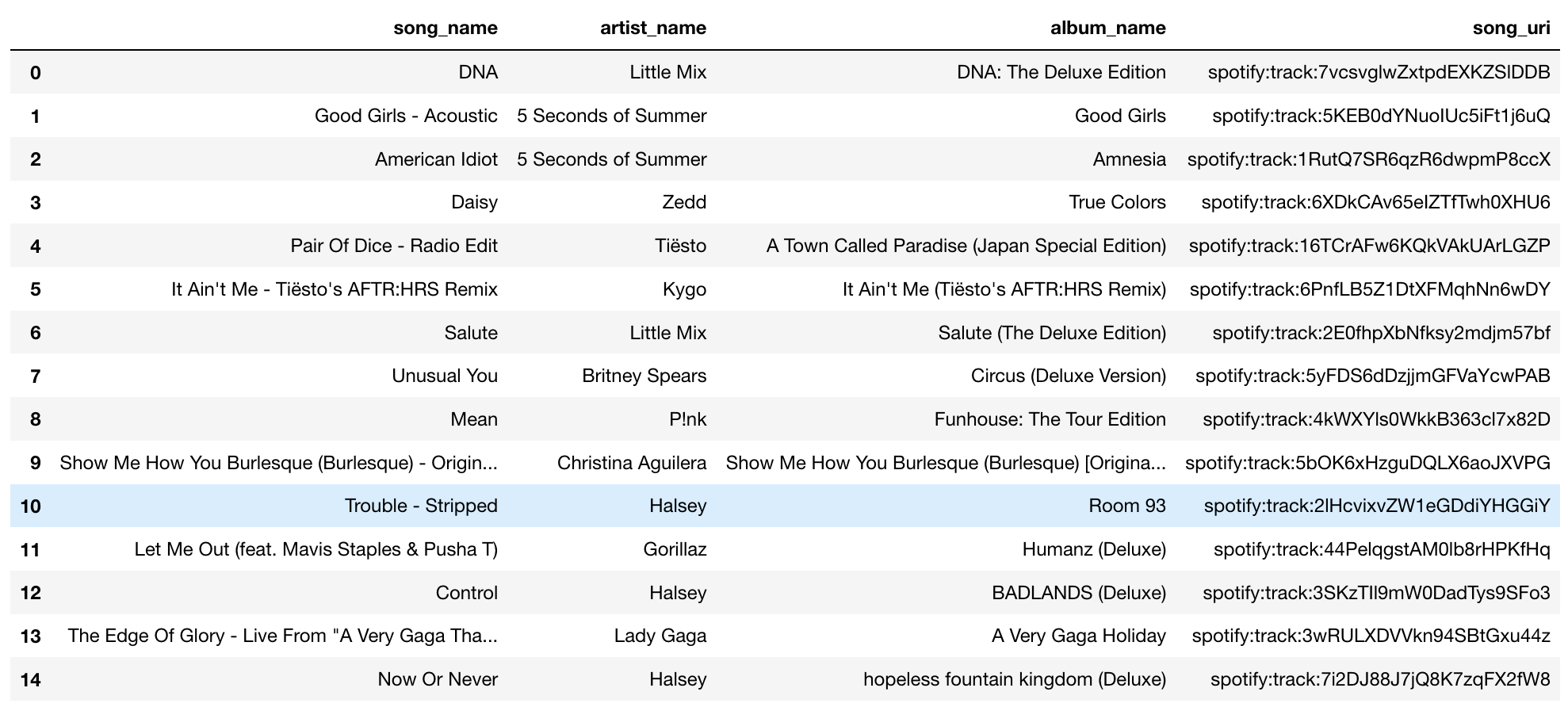
ok, it’s also not good, no Korean songs, but it recommends music from P!ink, Gorillaz, Lady Gaga, Britney Spears. This might be because these songs might sound somewhat similar to the songs in the playlist, so this model might still perform better than the simple model.
There’s a few important things to notice here:
- Even if we use cosine similarity, we might not recommend good songs if we mis-classify the genre. So classifying genre correctly is key. Also, we might want to consider classifying more genre’s other than the five we used.
- Language could play a role here. If the songs from a playlist are all in spanish, we should recommend spanish songs. Sadly, getting language data was not direct or easy for every song and we decided not to use it in this case.
Conclusion and Future Work
Our work resulted in a model that, based on the prediction of the gender of a given playlist, recommends songs that closely match the features of the songs contained in that given playlist. While we understand the limitations of our work and its contribution, we are thankful for how much we have learned and the accomplishments achieved throughout the project, particularly by tackling some challenges that we did not face during the course, making this project complimentary to the rest of the class.
A few instances of these challenges included collecting data by using Spotify’s Web API, working with an unsupervised learning case, building a website, and finding a methodology to recommend songs appropriately to a given playlist. The support from the Data Science teaching team, together with our literature review, was paramount in helping us deal with these challenges. In testing our work, we achieved XX% accuracy on the prediction of our model, and by listening to a sample of songs recommended to a given playlists, we saw (subjectively) that our model satisfactorily recommends songs aligned with the characteristics of a given playlist.
We also recognize that there are ample areas in which our work could be improved, including, but not limited to:
- Classification
- Further breaking down the classification of genres
- Including other aspects (beyond pure gender) in the classification of the songs, such as whether the song is instrumental
- Features
- Increase the number of features used
- Include features that describe the users (eg: age, language, location)
- Further explore variable selection methods (Lasso, Ridge, forward and backward selection)
- Use lyric features as predictors
- Model improvement
- Test other machine learning models (eg: Neural Networks, Support Vector Machine)
- Further tune the hyperparameters of the models we have used (eg: tree depths and number of trees in AdaBoosting)
- Data Set (our sample)
- Use larger datasets for the sources we used (eg: more playlists in the train/test sets, or for the pool of songs to be recommended)
- Include other sources of data to compliment what we have used (eg: Million Song Dataset, Lyrics Wiki)
- Song Suggestion
- Adjust our cosine similarity model to suggest songs in the proportion of the genres of songs in the given playlist (as opposed to suggesting all songs of the same genre as the predicted genre of the playlist)
- Explore other methods for recommending songs